
「社内の機密データを守りながら、話題の生成AIを活用したい」
「ChatGPTの利用料が社員数分かさみ、コスト削減を迫られている」
「インターネットがつながらない現場でもAIを使いたい」
こうした切実な課題を抱える企業の経営者様やDX担当者様の間で、今、「ローカルLLM(大規模言語モデル)」への注目が急速に高まっています。
クラウド型のAIサービスは手軽ですが、データが外部サーバーに送信されるという構造上、セキュリティポリシーの厳しい企業や、顧客のプライバシー情報を扱う現場では導入のハードルが高いのが現実です。また、API利用料という変動費も経営の予見性を下げる要因となります。
そこで解決策となるのが、自社のPCやサーバー内で完結して動作する「ローカルLLM」です。
本記事では、2026年最新の「ローカルLLM おすすめモデル」の徹底比較から、失敗しないためのPCスペック選定、社内データを読み込ませる「RAG」の構築、そして導入後の運用リスクまで、必要な知識を網羅的に、かつ専門用語を噛み砕いて解説します。
これを読めば、なぜ今ローカルLLMが選ばれるのか、そして自社にはどのモデルと機材が必要なのかが明確になるはずです。
(ローカルLLMの仕組みについて詳しく解説した記事はこちらからご覧いただけます!)
目次
なぜ今「ローカルLLM」なのか?クラウド型との決定的な違い

まずは、ChatGPTやGeminiなどの「クラウド型」と、今回ご紹介する「ローカル型」の本質的な違いについて、ビジネスの視点で深掘りします。
1. 鉄壁のセキュリティ:データは一歩も外に出ない
クラウド型AIの最大のリスクは、入力したデータが学習に利用されたり、サーバーへの通信経路上で漏洩したりする可能性がゼロではない点です。規約で「学習しない」とされていても、コンプライアンス部門の許可が下りないケースは多々あります。
一方、ローカルLLMは、インターネット回線を切断した状態(オフライン)でも動作します。
- 会議の議事録(未発表の新製品情報を含む)
- 顧客の個人情報が含まれる相談ログ
- 独自の製造ノウハウやプログラムコード
これらを処理する際、データはあなたの目の前にあるPC(または自社サーバー)の中で処理され、一歩も外に出ません。この「物理的な安心感」こそが、金融機関や製造業、医療分野でローカルLLMが選ばれる最大の理由です。
2. コスト構造の変革:変動費から固定費へ
クラウド型は、使えば使うほど課金される「従量課金(または月額サブスクリプション)」です。社員数が増え、利用頻度が上がれば、コストは青天井に膨らみます。
ローカルLLMは「初期投資型」です。高性能なPCを購入する費用はかかりますが、導入後はどれだけAIを使っても、かかるのは電気代のみ。
例えば、24時間稼働して膨大なドキュメントを読み込み続けるような自動化ボットを作る場合、クラウドでは莫大なAPI利用料がかかりますが、ローカルなら実質無料です。長期的に見れば、コストパフォーマンスは劇的に向上します。
3. BCP(事業継続計画)対策としての強み
クラウドサービスは、提供側のサーバーダウンや、通信障害の影響を直接受けます。業務の根幹にAIを組み込んだ場合、AIが止まることは業務停止を意味します。
自社環境で動くローカルLLMなら、外部環境に左右されず、安定して業務を継続することが可能です。
AI導入の無料相談はこちらから
失敗しない「スペック選定」の極意
ローカルLLM導入で最も多くの担当者が頭を悩ませるのが、「どんなPCを買えばいいのか?」というハードウェアの問題です。ここでは、PC初心者の方にもイメージしやすいよう、例え話を使って解説します。
AIを動かすための「3つの神器」
AIを快適に動かすには、以下の3つのパーツのバランスが重要です。
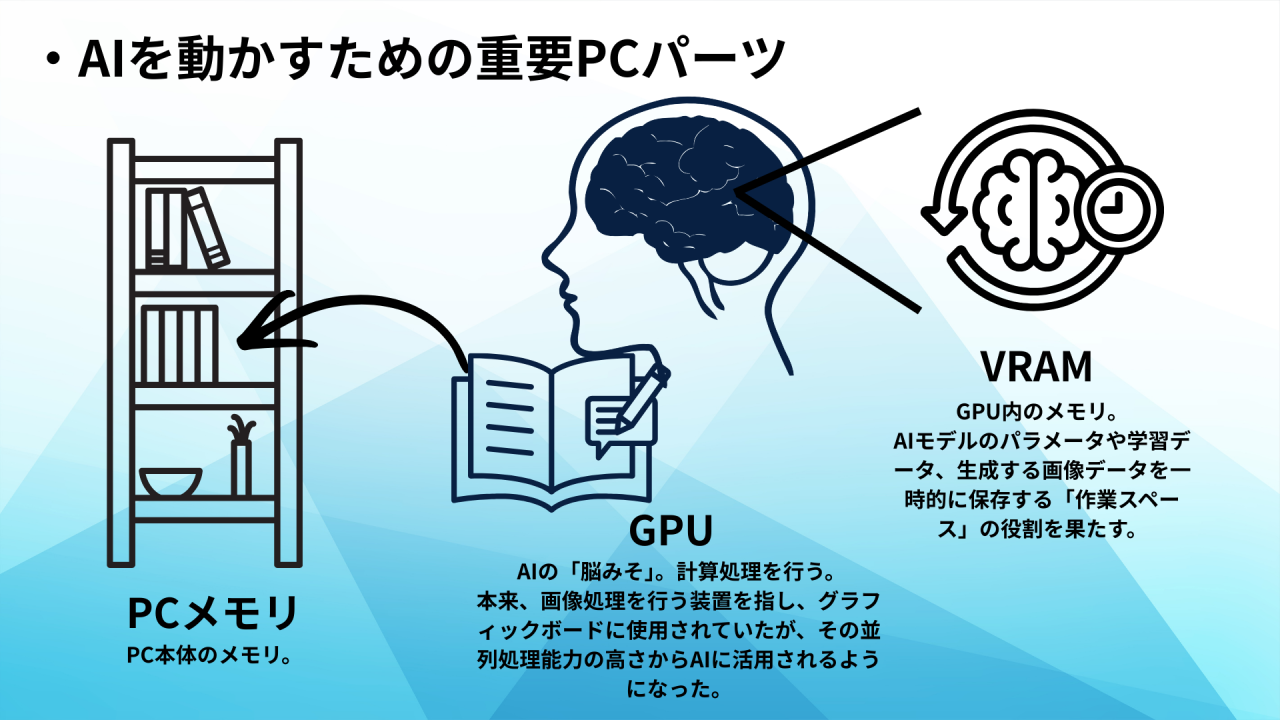
- GPU(グラフィックボード):AIの「脳みそ」
最も重要なパーツです。NVIDIA(エヌビディア)社の「GeForce」シリーズなどが主流です。AIの計算処理を専門に行います。 - VRAM(ビデオメモリ):AIの「作業机」
GPUに搭載されているメモリです。ここが狭いと、大きなAIモデル(分厚い辞書)を広げることができず、動作すらしないことがあります。 - システムメモリ(RAM):PC全体の「作業スペース」
PC自体のメモリです。GPUにデータを送る前の一時保管場所として、最低でも32GB、できれば64GBあると安心です。
最も重要なのは「VRAM」の容量
モデルの賢さ(パラメータ数)と、必要なVRAM容量には明確な関係があります。ここでは、現在主流の技術である「量子化(モデルを圧縮して軽くする技術)」を使用した場合の目安を示します。
| モデル規模 | パラメータ数 | 必要VRAM | 推奨GPU | ビジネス用途のイメージ |
| 軽量級 | 70億〜90億 (7B-9B) | 8GB以上 | RTX 3060 / 4060 | 【個人・検証用】 メールの下書き、簡単な翻訳、アイデア出し。ノートPCでも動作可能。 |
| 中量級 | 120億〜200億 (12B-20B) | 12GB〜16GB | RTX 4070 Ti SUPER RTX 4080 | 【実務導入の標準】 長文の要約、複雑な指示の理解、日本語文書の作成。一般的なデスクトップPCで導入可能。 |
| 重量級 | 700億 (70B) | 24GB×2枚 | RTX 3090 / 4090 (2枚差し) | 【高性能サーバー】 GPT-4レベルの高度な推論、専門知識を問うタスク、大規模RAG。 |
【結論】
これからローカルLLMを導入する企業様には、VRAM 16GBを搭載したPC(RTX 4070 Ti SUPER または 4080)の購入を強くおすすめします。このスペックがあれば、現在主流のほとんどの商用モデルを快適に試すことができ、コストパフォーマンスも最適です。
VRAM容量別・おすすめモデル早見表(2026年版)
「自分のPCでどのモデルが動くか」という疑問に直接答えるため、VRAM容量別の推奨モデルをまとめました。なお、ここでの容量はQ4量子化(4bit圧縮)を使用した場合の目安です。量子化なし(フルサイズ)では必要VRAMが2〜3倍になります。
| VRAM容量 | 動かせるモデルの目安 | おすすめモデル(2026年3月時点) | 向いている用途 |
| 8GB(RTX 3060/3070等) | 〜7Bパラメータ(Q4) | Qwen3 4B・Gemma 3n 4BLlama 3.2 3B | 試験的導入・軽量タスク・翻訳・個人利用 |
| 12〜16GB(RTX 4070/4080等) | 〜14Bパラメータ(Q4) | Qwen3 8B〜14B・Phi-4DeepSeek-R1 7B | 実用水準の日本語生成・RAG・コーディング補助 |
| 24GB以上(RTX 4090・A100等) | 30B〜70Bパラメータ(Q4) | Qwen3 32B・DeepSeek-V3.2Llama 3.3 70B | 高精度な推論・複雑なコード生成・企業向け本格運用 |
| Apple Silicon(M2/M3 Max以上) | 統合メモリを活用(実質32GB〜) | Qwen3 32B・Llama 3.3 70B | macOS環境での高性能ローカルLLM運用 |
VRAM容量の簡易計算式:「パラメータ数(B)の半分がGB単位の必要VRAM目安(Q4量子化時)」。例:14Bモデル ≒ 約7GB VRAM必要。
【2026年版】おすすめ主要モデル徹底比較
ハードウェアが決まれば、次はソフトウェア(AIモデル)選びです。世界中で公開されている数千のモデルの中から、ビジネス利用に耐えうる「四天王」をご紹介します。
1.Qwen3(Alibaba Cloud)〜2026年、日本語ローカルLLMの最有力候補〜
2025年4月にAlibaba Cloudがリリースした Qwen3シリーズ は、2026年現在のローカルLLM界隈で最も注目されているモデルファミリーです。前世代のQwen2.5と比較して同じパラメータ数でも大幅に性能が向上しており、「Qwen3-14BがQwen2.5-32B相当の性能を発揮する」とも評されています。
日本語性能が特に優秀で、ビジネス文書の作成・要約・翻訳・社内データを使ったRAG構築まで幅広いタスクで高い精度を発揮します。Apache 2.0ライセンスで商用利用も自由なため、企業導入に最もおすすめできるモデルの一つです。
| 項目 | 内容 |
| 開発元 | Alibaba Cloud |
| パラメータ展開 | 0.6B〜32B(Dense) / 30B-A3B・235B-A22B(MoE) |
| 日本語性能 | 優秀(2026年現在のローカルLLMでトップクラス) |
| 必要VRAM目安 | 8GB以上(4B/Q4)、16GB以上(14B/Q4)、24GB以上(32B/Q4) |
| ライセンス | Apache 2.0(商用利用可) |
| おすすめ用途 | 日本語文書作成・RAG・コーディング・汎用タスク全般 |
| Ollamaコマンド | ollama run qwen3:8b または ollama run qwen3:14b |
VRAMが限られている場合は、MoEアーキテクチャの「Qwen3-30B-A3B」も選択肢です。総パラメータ30Bですが実際に稼働するのは3Bのみのため、16GB VRAMでも高品質な出力が得られます。
2. DeepSeek-R1(DeepSeek)〜複雑な推論・コード生成に圧倒的な強み〜
中国のDeepSeek社が開発したDeepSeek-R1は、2025年初頭に「GPT-4oに匹敵する推論性能を持ちながら完全オープンソース(MITライセンス)」として世界的な注目を集めたモデルです。複雑な論理的思考・数学・コード生成の領域で特に強みを発揮します。
「AIに考えさせる」思考プロセス(Chain of Thought)が出力に含まれるため、複雑な問題に対して人間の思考に近い推論プロセスで回答を生成します。コード生成や法律・医療など専門性の高い分析を社内で行いたい企業担当者に特に向いています。
| 項目 | 内容 |
| 開発元 | DeepSeek |
| パラメータ | 7B〜671B(ローカル向けは7B・8Bが一般的) |
| 日本語性能 | 実用水準(英語・コードが主戦場だが日本語も対応) |
| 必要VRAM目安 | 8GB以上(7B/Q4)、16GB以上(14B/Q4) |
| ライセンス | MIT(オープンソース・商用利用可) |
| おすすめ用途 | 複雑な推論・コード生成・論理分析・専門文書の読解 |
| Ollamaコマンド | ollama run deepseek-r1:7b3. Gemma 3n(Google)〜マルチモーダル対応の軽量秀才〜 Googleが2025年に発表したGemma 3n、前世代のGemma 2から大幅に進化し、テキストだけでなく画像・音声にも対応したマルチモーダルモデルです。VRAM 8GBの一般的な環境でも高い性能を発揮する軽量設計が特徴で、「性能と手軽さのバランスが最も良い」と評価されています。 特に日英翻訳タスクでの精度が高く、Googleの多言語トークナイザーの強化により、少ないVRAMでも自然な日本語出力が可能です。PCのスペックに不安がある方が最初に試すモデルとして最適です。 項目 内容 開発元 パラメータ 1B・4B・12B・27B 日本語性能 良好(翻訳・軽量タスクで特に優秀) 必要VRAM目安 4GB以上(1B)、8GB以上(4B/Q4)、12GB以上(12B/Q4) ライセンス Gemma利用規約(商用利用可能・要確認) おすすめ用途 日英翻訳・軽量タスク・マルチモーダル処理・低スペック環境 Ollamaコマンド ollama run gemma3:4b または ollama run gemma3:12b |
3. Gemma 3n(Google)〜マルチモーダル対応の軽量秀才〜
Googleが2025年に発表したGemma 3n、前世代のGemma 2から大幅に進化し、テキストだけでなく画像・音声にも対応したマルチモーダルモデルです。VRAM 8GBの一般的な環境でも高い性能を発揮する軽量設計が特徴で、「性能と手軽さのバランスが最も良い」と評価されています。
特に日英翻訳タスクでの精度が高く、Googleの多言語トークナイザーの強化により、少ないVRAMでも自然な日本語出力が可能です。PCのスペックに不安がある方が最初に試すモデルとして最適です。
| 項目 | 内容 |
| 開発元 | |
| パラメータ | 1B・4B・12B・27B |
| 日本語性能 | 良好(翻訳・軽量タスクで特に優秀) |
| 必要VRAM目安 | 4GB以上(1B)、8GB以上(4B/Q4)、12GB以上(12B/Q4) |
| ライセンス | Gemma利用規約(商用利用可能・要確認) |
| おすすめ用途 | 日英翻訳・軽量タスク・マルチモーダル処理・低スペック環境 |
| Ollamaコマンド | ollama run gemma3:4b または ollama run gemma3:12b |
4. Phi-4(Microsoft)〜コーディングと数学で大型モデルに匹敵する小型精鋭〜
MicrosoftのPhi-4は、前世代のPhi-3.5から大幅に性能向上した14Bパラメータのモデルです。「あえて小さく作る」Microsoftの設計思想はPhi-4でも健在で、学習データの質を極限まで高めることでコーディングや数学的推論では30B〜70Bクラスのモデルに匹敵するスコアを記録しています。
14BというサイズはVRAM 16GBで快適に動作する「ちょうどいいサイズ感」で、社内にプログラマーがいる企業のコーディングアシスタントとして特に有効です。インターネット環境がない工場や現場でのマニュアル参照・コード補助にも最適です。
| 項目 | 内容 |
| 開発元 | Microsoft |
| パラメータ | 14B(SLM:Small Language Model) |
| 日本語性能 | 実用水準(英語・コードが主力。日本語も対応) |
| 必要VRAM目安 | 8GB以上(Q4_K_M量子化時)、16GB以上(Q8量子化・高精度運用時) |
| ライセンス | MIT(商用利用可) |
| おすすめ用途 | コーディング補助・数学的推論・オフライン環境・低コスト運用 |
| Ollamaコマンド | ollama run phi4 |
ローカルLLMの選定から構築まで、専門家と一緒に進めたい企業様へ。EQUES AI DX寺子屋では、社内でのAI活用を基礎から実践まで支援しています。まずはお気軽にご相談ください。
自社データをAIに組み込む「RAG」の威力

ローカルLLMを導入する企業の多くが目指すのが、RAG(Retrieval-Augmented Generation / 検索拡張生成)の構築です。
RAGとは何か?
通常のAIは、学習した過去の知識しか持っていません。そのため、あなたの会社の「最新の製品仕様書」や「先週の会議の内容」については何も知りません。
RAGは、AIに「カンニングペーパー(社内データ)」を渡して、それを見ながら回答させる技術です。
ローカルRAGの活用ユースケース
- 社内ヘルプデスクの自動化
「交通費精算の規定はどうなっていたっけ?」「有給休暇の申請フローは?」といった社員からの質問に対し、社内規定(PDF)を参照してAIが即答します。総務部の問い合わせ対応工数を劇的に削減できます。 - 技術伝承・マニュアル検索
熟練技術者が残した膨大な日報や技術文書をAIに読み込ませます。若手社員が「このエラーが出た時の対処法は?」と聞けば、過去の事例から解決策を提示してくれます。 - 契約書チェック支援
過去の法務チェック済み契約書をデータベース化し、新しい契約書案との差異やリスクを洗い出させます。
これら全てを、外部にデータを一切送信せずに行えるのが、ローカルLLM×RAGの真骨頂です。
初心者でもできる!導入手順とツール
「コマンドライン(黒い画面)での操作は難しそう…」と心配される必要はありません。現在は、直感的に使える素晴らしいツールが揃っています。
手順1:AIの「エンジン」を入れる(Ollama)
Ollama(オラマ)というツールを使います。これは、複雑な環境構築をワンクリックで行える画期的なソフトです。
- 公式サイトからインストーラーをダウンロード。
- インストール後、使いたいモデル名(例:llama3.1)を指定するだけで、自動ダウンロードとセットアップが完了します。
手順2:GUI派におすすめ「LM Studio」でモデルを動かす
Ollamaはコマンド操作が必要ですが、LM Studioを使えばグラフィカルな画面(GUI)でモデルのダウンロードから実行まですべて完結できます。エンジニアでない方や、コマンドライン操作に不慣れな方に特におすすめです。
- LM Studio公式サイト(https://lmstudio.ai)にアクセスし、自分のOS(Windows/macOS)に対応したインストーラーをダウンロード・インストール
- アプリを起動し、上部の「Discover」タブを開く
- 検索ボックスに試したいモデル名(例:qwen3、gemma3)を入力して検索
- 表示されたモデルのサイズ(4B・8B等)を確認し、自分のVRAMに合ったものの「Download」ボタンをクリック
- ダウンロード完了後、上部の「Chat」タブに移動してモデルを選択するとチャットが開始できる
LM StudioはOllamaと同様に無料で利用できます。ChatGPTに近い操作感でローカルLLMを体験できるため、社内にAI活用を広めるための入口としても最適です。
ローカルLLMの導入・構築について、さらに詳しく知りたい方はEQUESにご相談ください。貴社の目的・スペック・予算に合わせた最適な構成をご提案します。
導入前に知っておくべきリスクと注意点

良いことばかりではありません。ローカルLLM特有の課題も理解しておく必要があります。
1. 「ハルシネーション(もっともらしい嘘)」
ローカルLLMに限らず、生成AIは事実ではないことを自信満々に語ることがあります。業務利用の際は、「AIの回答を必ず人間が確認する」フローを組み込むか、RAGを使って「根拠となるドキュメント」を必ず提示させる設定にする必要があります。
2. ライセンスの複雑さ
オープンソースモデルは「無料」ですが、「無条件」ではありません。
- 商用利用は可能か?(Non-Commercialライセンスではないか?)
- クレジット表記(「Llamaを使用しています」等の記載)が必要か?
これらをモデルごとに確認する必要があります。
3. セキュリティ設定の落とし穴
「ローカルだから安全」と過信してはいけません。社内ネットワークに接続する場合、アクセス権限の設定を誤ると、社員Aが見てはいけない人事データを社員BがAI経由で引き出せてしまう可能性があります。
また、「プロンプトインジェクション(AIを騙して不適切な回答を引き出す攻撃)」への対策も、自社で行う必要があります。
費用対効果の試算と今後の展望

コストシミュレーション
【条件】社員20名で3年間、業務支援AIを利用する場合
- クラウド型(ChatGPT Teamプラン等):
月額約4,500円 × 20名 × 36ヶ月 = 約324万円
※ここに追加で、データ連携などの開発費がかかる場合があります。 - ローカル型:
ハイスペックPC(GPU 2枚構成)購入費:約80万円
電気代(月5,000円と仮定):約18万円
保守運用・人件費(概算):約100万円
合計:約198万円
このように、一定規模以上の利用であれば、ローカルLLMは圧倒的なコストメリットを出せる可能性があります。何よりも、「情報漏洩リスクゼロ」という価値は金額換算できないほど大きいです。
今後の展望:AIエージェントへ
現在は「人がチャットで指示して、AIが答える」形式ですが、近い将来、ローカルLLMは「自律型エージェント」へと進化します。
「PC内のフォルダを整理しておいて」「届いた請求書を会計ソフトに入力しておいて」といった指示だけで、AIが自律的にPCを操作して業務を完遂する時代がすぐそこまで来ています。
今、ローカルLLMの環境を整えておくことは、こうした次世代の業務自動化への重要な布石となるのです。
まとめ:自社に最適なAI活用の第一歩を
ローカルLLMは、セキュリティ、コスト、カスタマイズ性の面で、企業のAI活用を次のステージへと押し上げる強力な選択肢です。
- まずはスモールスタートで: 手元のPCにOllamaを入れ、Phi-3.5などの軽量モデルから試してみる。
- 実務へ展開: VRAM 16GB以上のPCを用意し、Llama 3.1やMistral NeMoで社内RAGを構築する。
しかし、「どのモデルが自社の業務に最適なのか判断が難しい」「RAGの精度が上がらず困っている」「セキュリティ設定に不安がある」といった専門的な課題に直面することも事実です。
東大発のAI専門家が、あなたのAI導入を「伴走」します

株式会社EQUES(エクエス)は、東京大学松尾研究所発のAIスタートアップ企業です。
私たちは、単なるシステム開発ではなく、お客様の社内AI人材を育成し、共に課題解決に取り組む「伴走型技術開発」を提供しています。
弊社が提供するサービス「AIDX寺子屋」では、月額定額で東大出身のAI専門家集団にチャットで相談し放題。
- 「この業務に使えるローカルLLMはどれ?」
- 「RAGの回答精度を上げるためのコツは?」
- 「社内PCのスペック選定を手伝ってほしい」
こうした具体的なお悩みに対し、専門家が迅速かつ親身に回答いたします。プランA(月額20万円〜)では、チャット相談に加えて月1回のオンラインミーティングも実施。貴社のAIプロジェクトを成功へと導きます。
AIの進化は待ってくれません。
セキュリティと効率化を両立する「ローカルLLM」の導入を、私たちと一緒に始めませんか?
まずはお気軽に、貴社の現状や課題をご相談ください。
関連記事
▶ ローカルLLMとは? 開発・導入からPCスペックまで徹底解説


