
ChatGPTをはじめとする生成AIのビジネス活用が急速に進む中、弊社EQUESにも、こんなご相談が増えています。
- 「社内の機密情報や顧客データをAIに入力するのが不安…」
- 「汎用AIでは物足りない。自社業務にフィットしたAIを作れないか?」
- 「ネット接続が不安定でも、安定して使えるAIはない?」
こうした悩み、あなたも感じたことがあるかもしれません。クラウド型のAIサービスは便利な一方で、情報漏洩リスクや機能の限界といった課題も抱えています。
それらを解決する有力な選択肢が、今注目されている「ローカルLLM(大規模言語モデル)」の導入です。
ローカルLLMとは、インターネットに依存せず、自社のPCやサーバー、あるいは自分のノートパソコンなどのローカル環境で動作するAIのこと。私たちも現場で多くの導入・開発支援を行う中で、この技術がプロジェクト成功のカギとなった事例を数多く見てきました。
本記事では、AI導入・開発支援のプロである弊社が、
- ローカルLLMとクラウドLLMの違い
- 導入・開発前に知っておきたいメリット・デメリット
- ローカルLLMの開発・構築の基本的な流れ
- 2026年最新のおすすめ日本語モデル
- 導入の始め方や必要スペック、活用事例
などを、わかりやすく網羅的に解説します。
読み終える頃には、ローカルLLMがあなたの会社にとって最適な選択肢かどうか、そしてどのように導入・開発を進めればよいか、明確な判断ができるはずです。
本記事があなたやあなたの組織のAI活用を次のステージへ進める一助となれば幸いです。
目次
そもそもローカルLLMとは?クラウドLLMとの違い
「最近よく聞くローカルLLMって、一体何?」「いつも使っているChatGPTとは違うの?」 そんな疑問をお持ちの方も多いのではないでしょうか。
一言でいうと、ローカルLLMとは「あなたのパソコンや社内のサーバーなど、手元の閉じられた環境(ローカル環境)で直接開発・構築し、動かすAI」のことです。
この説明だけでは、まだピンとこないかもしれません。そこで、多くの人が使い慣れているクラウドLLM(ChatGPT, Google geminiなど)と比較すると、その違いが非常によくわかります。
AIがどこで動いているか?それが最大の違い
私たちが普段、ブラウザから利用するChatGPTやGoogleのGeminiといったAIは「クラウドLLM」と呼ばれます。これは、AIのプログラム本体が、サービスを提供するGoogleやOpenAI(ChatGPT)といった企業の巨大なコンピューター(クラウドサーバー)上にあり、私たちはインターネットを通じてその機能を使わせてもらっている、という仕組みです。
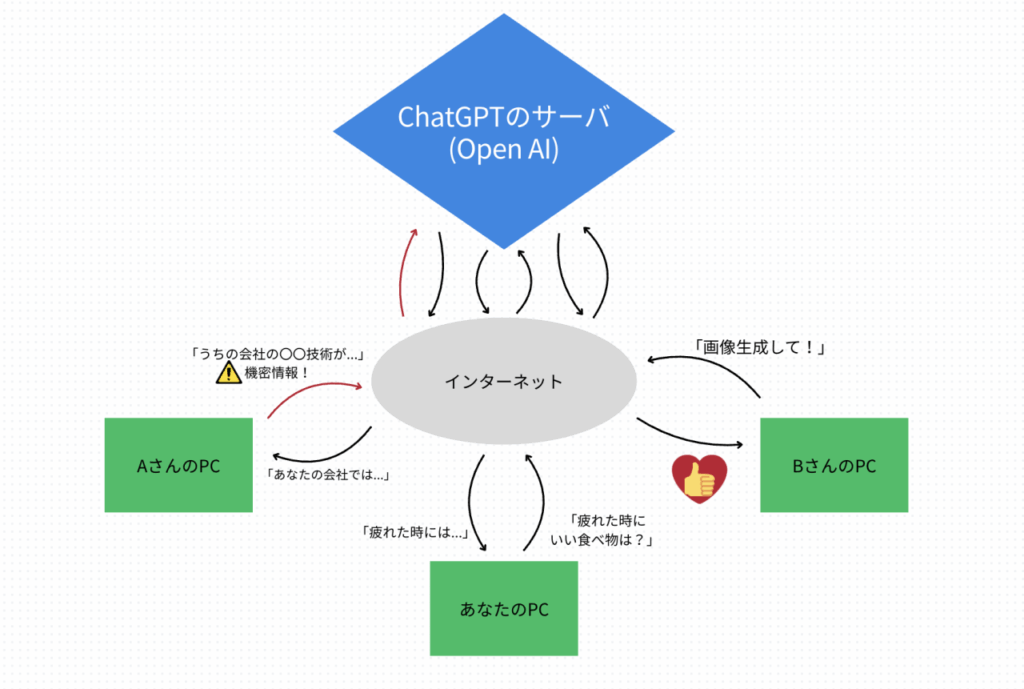
【図1】クラウドLLMの仕組み。ユーザーが入力したデータはインターネットを経由して外部のサーバーで処理される。
クラウドLLMは、自分のPCに負荷をかけることなく、いつでも最新・最高のAIを手軽に利用できるのが大きなメリットです。しかしその一方で、入力したデータは必ずインターネットを通じて外部のサーバーに送信されます。そのため、「社内の機密情報や個人情報を入力するのはセキュリティ的に不安だ」という懸念が常に付きまといます。
それに対してローカルLLMは、AIのモデル自体を自分のPCや社内サーバーにダウンロードしてきて、その中で動かします。
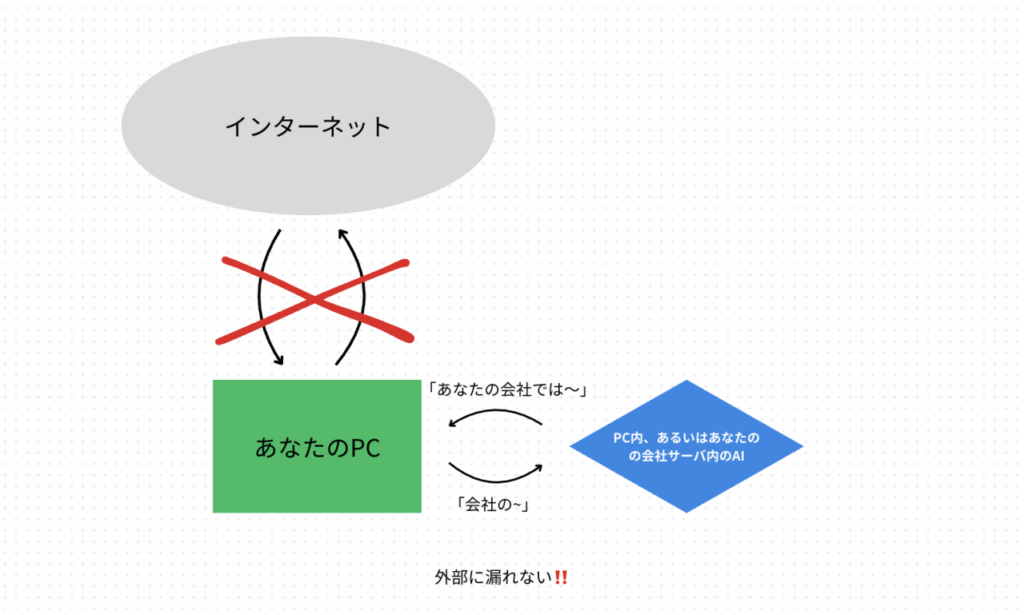
▲【図2】ローカルLLMの仕組み。データもAIの処理もすべて手元のPCやサーバー内で完結する。
この仕組みの最大のメリットは、入力したデータがPCやサーバーから一切外に出ないことです。インターネットに接続していないオフライン環境でも利用できるため、情報漏洩のリスクを限りなくゼロに近づけることができ、非常に高いセキュリティを確保できます。
クラウドLLMとローカルLLMの比較まとめ
| 比較項目 | クラウドLLM (例: ChatGPT, Gemini) | ローカルLLM (例: Llama 3, Mistral) |
| 動作場所 | インターネット上の外部サーバー | 手元のPC、社内サーバー |
| データ | 外部に送信される | 外部に送信されない |
| 手軽さ | ◎ サインアップするだけ | △ 導入・構築に手間がかかる |
| PC負荷 | ほぼ無い | 高い(開発時) |
| セキュリティ | △ サービス提供者に依存 | ◎ 非常に高い |
| ネット接続 | 必須 | 不要 |
このように、クラウドLLMとローカルLLMの最も大きな違いは、「AIがどこで動いているか」そして「あなたのデータが外部に出るか、出ないか」という点にあります。
この根本的な仕組みの違いが、次の章で解説する「なぜ今ローカルLLMが重要視されるのか」という理由に直結してくるのです。
なぜ今、ローカルLLMが重要視されるのか?注目の背景
なぜ今、これほどローカルLLMが注目されているのでしょうか。その背景には、大きく分けて3つのトレンドがあります。
1. セキュリティ・コンプライアンスへの強い要請
生成AI利用時の情報漏洩リスクや、世界的に強化されるデータ保護規制(コンプライアンス)を背景に、「機密データを外部サーバーに送信したくない」というニーズが急増しています。データを手元で完結させるローカルLLMの仕組みが、この時代の要請に完璧に応える形となりました。
2. AIモデルの劇的な進化と小型化
かつては専門機関の巨大な設備でしか動かせなかった高性能AIが、技術の進化により、一般的なPCでも扱えるほど高性能かつ小型化しました。特に、オープンソース(一般に公開されている)で優れたAIモデルが次々と登場したことで、誰もが高品質なAIを手元で動かす環境が整ったのです。
3. ビジネスニーズの深化とカスタマイズ要求
AI活用が本格化するにつれ、「自社の専門用語を理解させたい」「社内文書だけを学習させたい」といった、企業独自の深いカスタマイズ要求が高まっています。外部サービスの制約を受けずにモデルを自由に改良できるローカルLLMは、こうした専門的なニーズに応えるための最適な基盤となっています。
この「セキュリティ」「技術」「ビジネスニーズ」という3つの波が重なり合ったことで、ローカルLLMの重要性は急速に高まっているのです。
【徹底比較】ローカルLLM vs クラウドLLM あなたに最適なのはどっち?
ローカルLLMとクラウドLLM、それぞれに明確なメリット・デメリットがあり、どちらが一方的に優れているというわけではありません。
あなたの目的、予算、そして技術力によって最適な選択は異なります。ここでは、AI導入を検討する上で特に重要な6つの観点から両者を徹底比較します。この章を読めば、あなたにとってどちらが最適か、その輪郭がはっきりと見えてくるはずです。
一目でわかる!ローカルLLM vs クラウドLLM 比較表
まずは、両者の違いを一覧表で確認しましょう。
| 比較項目 | ローカルLLM | クラウドLLM (ChatGPT等) |
| (1) セキュリティ | ◎ 非常に高い | △ サービス提供者に依存 |
| (2) カスタマイズ性 | ◎ 高い(モデル内部も可) | 〇 限定的(API経由が主) |
| (3) コスト | 初期費用:高 / 継続費用:低 | 初期費用:低 / 継続費用:高 |
| (4) パフォーマンス | △ PCスペックに依存 | ◎ 常に最高レベル |
| (5) 導入・運用の手間 | △ 専門知識が必要 | ◎ 非常に簡単 |
| (6) オフライン利用 | ◎ 可能 | × 不可 |
各項目の詳細解説
なぜこのような評価になるのか、項目ごとに詳しく見ていきましょう。
(1) セキュリティ
これは両者の最も大きな違いです。ローカルLLMは、入力したデータがPCやサーバーから一切外に出ないため、物理的に情報漏洩のリスクを遮断できます。機密情報や個人情報を扱う上で、これ以上ない安心感があります。一方、クラウドLLMも提供事業者が堅牢な対策を講じていますが、データを外部に送信する以上、リスクをゼロにすることはできません
(2) カスタマイズ性
ローカルLLMは、オープンソースのモデルをベースに、モデルの内部構造まで手を入れて改良する「ファインチューニング」が可能です。これにより、自社の専門業務に完全に特化した、世界に一つだけのAIを開発できます。クラウドLLMのカスタマイズは、APIを通じて行える範囲に限られるため、ここまで開発の自由度はありません。
(3) コスト
コスト構造が正反対です。ローカルLLMは、AIを動かすための高性能PCやサーバーといった初期費用が高額になりがちです。しかし一度環境を構築すれば、どれだけ使ってもAPI利用料のような継続費用はかかりません(※電気代・人件費を除く)。 クラウドLLMは、初期費用はほぼゼロですが、使った分だけ料金が発生する従量課金制が基本です。本格的にビジネスで活用し、利用量が増えると継続費用が想定以上に膨らむ可能性があります。
(4) パフォーマンス
純粋なAIの性能や回答速度は、クラウドLLMに軍配が上がります。サービス提供者が莫大な投資で維持している最新・最高のAIをいつでも利用できます。
私も自分のノートパソコンでLM Studioというアプリを入れてローカルLLMを使っていますがパフォーマンスについては
- 生成にかかる時間 → PCの性能次第
- 回答のレベル・正確さ → クラウドLLMの方が上
という印象です。ちなみにMacBook Air2020を使っていますがストレスに感じるほど遅いことはありません。
(5) 導入・運用の手間
手軽さではクラウドLLMが圧勝です。アカウントを登録すれば、誰でもすぐに使い始められます。
ローカルLLMは、学生などが個人で動かすのは簡単ですが、会社などの組織単位で会社のサーバに導入し、本格的な開発・構築を行うとなると、環境構築、モデルの選定、アップデート対応など、専門的な知識と運用工数が必要です。
結論:あなたへのおすすめはどっち
ここまでの比較を踏まえ、あなたがどちらを選ぶべきかをまとめます。
☆ ローカルLLMがおすすめな人・企業
- セキュリティを最優先し、機密情報や個人情報を扱う(金融、医療、法務など)
- 独自の業務に特化したAIを深く開発・構築(カスタマイズ)したい
- APIの継続的なコストを避けたい、またはオフライン環境でAIを使いたい
☆ クラウドLLMがおすすめな人・企業
- 初期費用をかけず、とにかく手軽に最新のAIを試してみたい
- AIの運用に手間や専門人材をかけたくない
- 常に最高性能のAIを利用したい
【開発者向け】ローカルLLM導入・構築の3ステップ
ローカルLLMのメリットを理解した上で、次に技術的な視点、特に「どうやって導入・開発を進めるのか?」という疑問に答えます。
ここでは、ローカルLLMをビジネスで活用するための導入・構築プロセスを3つのステップに分けて解説します。
ステップ1:目的定義と要求スペックの明確化
まず、「なぜローカルLLMを構築するのか」という目的を明確にします。
「機密情報を扱いたい」「特定の社内文書に基づいた回答が欲しい」「オフライン環境での動作が必須」など、目的によって導入すべきモデルや開発アプローチが異なります。
同時に、必要なPCスペック(特にGPUのVRAM)やサーバー環境の要件定義を行います。
ステップ2:モデル選定と開発環境の構築
目的に合わせて、ベースとなるオープンソースのLLMを選定します。(例:Llama 3, Mistral, ELYZA-japanese-Llama-2 など)
モデルのサイズ(パラメータ数)、ライセンス、日本語性能などを比較検討します。
次に、選定したモデルを動かすための環境を構築します。Python環境の整備、必要なライブラリ(Hugging Face Transformers, LangChainなど)のインストール、GPUドライバの設定など、開発の土台を整えます。
以下の表は2026年3月時点での主要モデルを用途別に整理したものです。
【2026年最新版】用途別おすすめローカルLLMモデル
| モデル名 | 開発元 | 特徴 | 主な用途 | ライセンス |
| Qwen3(推奨) | Alibaba | 2026年の日本語対応ローカルLLMの事実上のスタンダード。14B〜32BモデルはVRAM 16GB以上で高品質な日本語生成が可能。コーディングにも強い | 日本語文書作成・コーディング・RAG構築 | 商用利用可(Apache 2.0) |
| Gemma 3n | 2025年6月登場。マルチモーダル対応(テキスト・画像・音声)。軽量で動作が速く、VRAM 8GBでも高い性能を発揮 | 軽量タスク・日英翻訳・マルチモーダル処理 | 商用利用可(Gemma利用規約) | |
| GPT-OSS-20B(gpt-oss) | OpenAI | OpenAIが初めてオープンソースとして公開。汎用性が高くOpenAI APIとの互換性あり。既存ツール(Cursor等)に即対応可能 | 汎用的なテキスト生成・既存OpenAIシステムの代替 | 要確認(最新ライセンス参照) |
| DeepSeek-V3.2 | DeepSeek | 汎用高性能モデル。コード生成・論理推論・エージェントタスクに強み。GPT-5相当の性能を発揮。VRAM 24GB以上推奨 | コード生成・複雑な論理推論・分析 | MIT(オープンソース) |
| Llama 3.3(70B) | Meta | 最も多くの派生モデルを持つ業界標準。コミュニティが広く、日本語特化派生モデルも豊富 | 汎用・RAG・コミュニティ活用 | Llama利用規約(商用可) |
| Mistral 7B | Mistral AI | 軽量ながら高性能。VRAM 8GBでも動作。英語タスクに強い | 英語中心のタスク・低スペック環境 | Apache 2.0(商用利用可) |
※ 各モデルのライセンスは商用利用の可否を必ずご確認ください。上記は2026年3月時点の情報です。最新情報は各モデルの公式リポジトリをご参照ください。
ステップ3:開発(ファインチューニング)と運用
環境が整ったら、いよいよ開発フェーズです。多くの場合、「ファインチューニング」と呼ばれる手法を用います。これは、自社のマニュアルや過去の問い合わせ履歴といった独自データをモデルに追加学習させ、特定のタスクに特化させる開発作業です。
この開発プロセス(RAGやファインチューニング)が、ローカルLLM活用の肝となります。構築したモデルをテストし、精度を評価しながら継続的に改善していく運用プロセスも重要です。
ローカルLLMに必要なPCスペック・デバイス
「ローカルLLMを導入したい!」と思ったとき、多くの方が最初に直面するのが「一体、どんなPCが必要なんだろう?」という壁です。
実は、チャットで少し試すだけの場合と、本格的なAI開発を行う場合とでは、求められるPCスペックは全く異なります。ここでは、ローカルLLMの用途を3つのレベルに分けて、それぞれに必要なデバイスの要件を具体的に解説します。
最重要パーツはGPU!特に「VRAM」の容量がカギ
スペックの話に入る前に、最も重要なポイントをお伝えします。ローカルLLM用のPCで最も重要なパーツは、GPU(グラフィックボード)です。そして、GPUの性能の中でも特に「VRAM(ビデオメモリ)」の容量が決定的な役割を果たします。
なぜなら、LLM(大規模言語モデル)は、その名の通り巨大な「言葉の辞書」のようなものです。この辞書を作業机に広げておく場所がVRAMにあたります。
VRAM(作業机)が広ければ広いほど、より大きくて賢い辞書(LLMモデル)を快適に扱える、とイメージしてください。動かしたいLLMのモデルサイズ(7B、13B、70Bなど ※BはBillion=10億)によって、必要なVRAM容量が決まります。
RAM容量別・おすすめモデル早見表
ローカルLLMを動かすために最も重要なのはGPUのVRAM(ビデオメモリ)容量です。自分のPCのVRAMに合わせて以下から選択してください。
| VRAM容量 | 動作規模の目安 | おすすめモデル(2026年) | 用途 |
|---|---|---|---|
| 8GB(RTX 3070等) | 〜7Bパラメータ(量子化モデル) | Gemma 3n 4B・Llama 3.2 3B・Qwen3 4B(Q4量子化) | 軽量タスク・試験的導入・個人利用 |
| 16GB(RTX 4080等) | 〜14Bパラメータ | Qwen3 14B・Gemma 3n 12B・Llama 3.1 8B | 日本語文書作成・RAG・業務効率化 |
| 24GB以上(RTX 4090・A100等) | 30B〜70Bパラメータ | Qwen3 32B・DeepSeek-V3.2・Llama 3.3 70B(Q4) | 高精度な推論・複雑なコード生成・企業向け本格運用 |
| Apple Silicon(M2 Max/M3 Max) | 統合メモリ活用(実質32〜128GB) | Qwen3 32B・Llama 3.3 70B・GPT-OSS 20B | macOS環境での高性能ローカルLLM運用 |
VRAMが不足するとモデルの動作が著しく遅くなるか、起動自体ができない場合があります。「B数の半分(GB)がVRAMの目安」という簡易計算式も覚えておくと便利です(例:14Bモデル≒7GB以上のVRAMが必要)。
※VRAM、メモリなどの用語がわからない方はこちらからお読みください。
【レベル1】まずはお試し!入門レベルのPCスペック
- 目的: 比較的小規模なモデルを動かし、ローカルLLMがどんなものか体験する。
- GPU: NVIDIA GeForce RTX 3060 / RTX 4060
- VRAM: 12GB
- (※同じモデル名でもVRAMが8GB版など複数あるため注意が必要)
- メモリ (RAM): 16GB 以上
- CPU / ストレージ: 最近のモデルであればOK。高速なSSD推奨。
まずはここから。このスペックでも多くの小規模モデルを快適に試すことができ、ローカルLLMの始め方としては十分な構成です。
【レベル2】実用・開発向け!ミドルレンジのPCスペック
- 目的: より高性能なモデル(13B〜30Bクラス)を動かし、本格的な開発や実用的なタスクをこなす。
- GPU: NVIDIA GeForce RTX 4070 SUPER / RTX 4080 SUPER
- VRAM: 16GB 〜 24GB
- メモリ (RAM): 32GB 以上
- CPU / ストレージ: Core i7 / Ryzen 7 以上。1TB以上の高速NVMe SSD推奨。
本格的な活用やAI開発を目指すなら、このレベルのスペックを目標にしたいところです。多くの開発者がこの範囲のデバイスを使用しています。
【レベル3】本格運用・研究向け!ハイエンドPCスペック
- 目的: 70Bクラス以上の巨大モデルの実行や、独自のAIモデルを開発する「ファインチューニング」を行う。
- GPU: NVIDIA GeForce RTX 4090
- VRAM: 24GB (場合によってはプロ向けGPUの複数枚構成も視野に)
- メモリ (RAM): 64GB 〜 128GB 以上
- CPU / ストレージ: Core i9 / Ryzen 9 クラス。
これは、専門的な研究や企業でのAIサービス運用など、パフォーマンスを極限まで追求するためのプロフェッショナルな構成です。
補足:MacやGPUなしのPCでも動かせる?
- Macの場合: Apple Silicon(M1/M2/M3/M4)搭載のMacは、「ユニファイドメモリ」という仕組みにより、ローカルLLMと非常に相性が良いです。大容量のメモリ(32GB以上)を搭載したMacBook ProやMac Studioは、ミドルレンジPCに匹敵する性能を発揮することがあります。
- GPUなし(CPU実行)の場合: Llama.cppといったツールを使えば、GPU非搭載のPCでもCPUでモデルを動かすことは可能です。ただし、生成速度はGPUに比べて大幅に遅くなるため、「とりあえず動かしてみる」という体験用途に限られます。
クイックスタート!
- まずはパソコンにローカルLLMのアプリをインストールしてみましょう
- ローカルLLMアプリの一つLM Studioのインストール方法はこちら!
最適なPCスペック選びはEQUESにご相談ください!
ここまで具体的なスペックを解説してきましたが、「結局、自分の目的に一番合うPCはどれ?」「BTOパソコンでどんな構成にすればいいか分からない…」と、かえって悩んでしまった方も多いのではないでしょうか。
弊社EQUESは、AI開発の専門知識を活かし、ローカルLLMの導入目的やご予算に応じた最適なハードウェアの選定からご相談に乗ることが可能です。PCスペック選びで迷ったら、ぜひ一度お気軽にお問い合わせください。
ローカルLLM導入・開発の具体的な事例

「高性能なPCが必要なことは分かったけれど、実際にどんなことに使えるの?」 ここでは、ローカルLLMの強みである「高いセキュリティ」「自由なカスタマイズ」「オフライン利用」を活かした、具体的な活用事例を3つの視点からご紹介します。
【経営層・ビジネス部門向け】機密情報を守り抜く!セキュアな社内AIアシスタント
企業の競争力の源泉である機密情報。これをクラウドAIに入力することに躊躇する経営者は少なくありません。ローカルLLMなら、その心配は不要です。
- 活用事例(1):社内文書検索システム(セキュアRAG)
社内規定、過去の議事録、製品マニュアル、財務データといった機密文書をローカルLLMに学習させます。社員は「昨年のAプロジェクトの最終報告書はどこ?」と自然な言葉で質問するだけで、AIが瞬時に該当箇所を提示。セキュリティが担保されているため、どんな機密文書でも安心してAIの分析対象にでき、社内の情報資産を最大限に活用できます。
- 活用事例(2):高セキュリティ社内チャットボット
人事評価や経費精算のルールなど、社員からの定型的な問い合わせに24時間対応するチャットボットを構築。個人情報を含むデリケートな質問にも、情報を外部に出すことなく安全に応対できます。
【開発者・エンジニア向け】外部に頼らない!自由なAI開発・コーディング支援
ソースコードは企業の重要な知的財産です。また、集中したい時や移動中にオフラインで開発したいというニーズも多くあります。
- 活用事例(3):セキュアなコーディング支援
手元のPCで動作するコーディング特化のローカルLLM(例: Code Llama)を導入し、開発エディタと連携。外部にソースコードを一切送信することなく、コードの自動補完やバグの修正、仕様書からのコード生成といった高度な支援を受けられ、開発効率が飛躍的に向上します。
- 活用事例(4):オフラインでの開発ドキュメント検索
飛行機の中や客先のサーバー室など、インターネットが使えない環境でも、技術ドキュメントを学習させたローカルLLMが最高の相談相手に。エラーメッセージの意味を尋ねたり、ライブラリの使い方を質問したりと、オフラインでも開発作業を止めることがありません。
【クリエイター・一般向け】ネット不要!いつでもどこでも創造活動
インターネット環境やクラウドサービスの利用規約に縛られず、自由な発想で創作活動に集中したい、という方にもローカルLLMは最適です。
- 活用事例(5):オフラインでの執筆・アイデア出し 移動中の新幹線やカフェで、ブログ記事の草稿作成や、小説のプロット整理、論文の要約などが可能に。インターネット接続を気にせず、いつでもどこでもAIを思考のパートナーとして使えます。
- 活用事例(6):完全プライベートな対話AI 自分の好きな性格や口調にカスタマイズしたAIと、誰にも見られることのないプライベートな空間で自由に対話できます。学習や趣味の壁打ち相手として、創造性を最大限に引き出してくれます。
このように、ローカルLLMは専門家だけのものではありません。セキュリティが最重要となるビジネスの現場から、開発者の生産性向上、個人の創造活動まで、アイデア次第でその活用事例は無限に広がります。
あなたの業務や環境に、ローカルLLMをどう活かせるか、ぜひ想像してみてください。
ローカルLLM導入の課題をEQUESがワンストップで解決します
ここまでローカルLLMの魅力や可能性について解説してきましたが、同時に「専門知識が必要そう…」「最適なPCを選ぶのが難しそう…」といった不安を感じた方もいらっしゃるのではないでしょうか。ローカルLLMの導入・開発には、環境構築、モデル選定、ファインチューニングといった専門知識が必要です。
弊社EQUESは、AI開発・導入のプロフェッショナルとして、お客様の課題に合わせた最適なローカルLLM構築をソフトウェア(知見・ノウハウ)とハードウェア(実行環境)の両面からワンストップで支援します。
課題(1) 専門知識の不足:技術顧問サービス「AI×DX寺子屋」
どんなに優れたツールも、どう活用すれば良いかという知見がなければ価値を発揮できません。「AI導入で何から手をつければいいか分からない」「技術的な疑問をすぐに解決したい」そんな声にお応えするのが、EQUESの技術顧問サービス「AI×DX寺子屋」です。
チャットで東大の専門家チームにいつでも気軽に質問でき、AIの活用方針に関する壁打ちから、具体的な実装の相談まで、まるで貴社の専属AIチームのように伴走します。
課題(2) 環境構築:ハードウェア選定から導入まで伴走サポート
ローカルLLMのパフォーマンスは、土台となるハードウェアによって決まります。しかし、無数にある選択肢から最適な一台を選ぶのは至難の業です。
EQUESでは、この記事で解説したようなPCスペックの選定はもちろん、ご予算や目的に合わせた最適なハードウェア構成のご提案から導入、さらに導入後の運用・保守サポートまで、責任を持って伴走します。「PC選びで失敗した」という高額なリスクを避け、スムーズなローカルLLM導入を実現します。
EQUESの伴走型技術開発でできること
- 開発要件定義・技術コンサルティング
- セキュアな開発環境の構築支援
- 独自データを用いたファインチューニング・RAG開発
- 導入後の運用・保守サポート
「まずは専門家の話を聞いてみたい」という方は、ぜひ弊社の無料相談や、AI活用のヒントが得られる「AI×DX寺子屋」をご活用ください。
専門家の知見(ソフトウェア)から、最適な実行環境(ハードウェア)まで。 ローカルLLMに関するお悩みは、どんな些細なことでもEQUESにご相談ください。あなたの会社に最適なAI活用の形を、一緒に見つけましょう。
個人利用 vs 企業導入|目的別ガイド
ローカルLLMの利用シーンは大きく「個人利用」と「企業導入」に分かれます。それぞれの目的・コスト感・推奨モデルをまとめました。
ぜひご参考ください。
| 比較項目 | 個人利用(エンジニア・研究者) | 企業導入(法人担当者) |
| 主な目的 | AI技術の学習・個人プロジェクトへの活用・プログラミング補助 | 機密データを扱うAIシステム構築・業務効率化・コスト削減 |
| 推奨環境 | 個人PC(VRAM 8〜16GB)Ollama / LM Studio | 社内サーバー(VRAM 24GB〜)カスタム環境・セキュリティ設計が必要 |
| 推奨モデル | Qwen3 4B〜14B・Gemma 3n・Llama 3.2 | Qwen3 32B・DeepSeek・GPT-OSS 20B |
| コスト感 | 初期費用:PCスペック次第(数万〜十数万円)継続費用:ほぼゼロ | 初期費用:サーバー・GPU投資(数十〜数百万円)継続費用:電気代・保守費のみ |
| 専門知識 | 基本的なコマンド操作・Python知識あれば可 | AI/MLエンジニアまたは専門ベンダーのサポートが必要 |
| セキュリティ設計 | 個人PCのセキュリティ設定で対応 | 社内ネットワーク設計・アクセス管理・監査ログ等が必要 |
まとめ
本記事では、ローカルLLMの基本から、クラウドLLMとの違い、導入・開発のメリット、そして具体的な構築ステップまでを解説しました。
- ローカルLLMの最大の強みは、データを外部に出さない「高いセキュリティ」と、自社仕様に改良できる「自由なカスタマイズ性」にあります。
- そのメリットを享受するには、「高性能なPC(特にGPU)」と、それを扱う「専門知識」という導入ハードルが存在します。
- ビジネスでの機密情報活用から個人の創造活動まで、アイデア次第でその活用方法は無限に広がります。
- このようにローカルLLMは、セキュリティとカスタマイズ性を両立させる強力なソリューションですが、その導入と開発には専門的な知見が必要です。
- 弊社は、「専門家の技術顧問」と「最適なハードウェア選定」の両面から、ローカルLLM導入の課題をワンストップで解決します。
ローカルLLMは、もはや一部の専門家だけのものではなく、多くの企業や個人にとって現実的で強力な選択肢となっています。
この記事が、あなたのAI活用を次のステージへ進めるための一助となれば幸いです。導入に関するご相談や、具体的なお悩みがあれば、どうぞお気軽に弊社までお問い合わせください。
関連記事はこちら
▶ ローカルLLMのおすすめモデル比較|RAG・スペック・商用利用まで解説
▶ AI セキュリティリスクと対策|企業がAIを安全に活用するための方法
▶ AIの作り方とは?開発プロセスと自社開発vs外注の判断基準


