
「社内の機密データを保護した状態で生成AIを活用したい」
「クラウド型APIに依存せず、自社環境で完結するAIシステムを構築したい」
「情報漏洩リスクを物理的に遮断できる方法を知りたい」
こうしたコンプライアンス要件やシステム要件を抱える情報セキュリティ責任者様やプロダクトマネージャー様の間で、現在「ローカルLLMの開発」への需要が高まっています。
クラウド型のAIサービスは、入力データがインターネット経由で外部のサーバーに送信される構造上、セキュリティポリシーが厳格な環境では導入が困難なケースが存在します。その解決策となるのが、自社のサーバーや端末内で完結して動作するローカルLLMです。
※ローカルLLMについて詳しく書いた記事はこちらをご覧ください→ローカルLLMとは? 開発・導入からPCスペックまで徹底解説 | EQUES
本記事では、ローカルLLMの導入に必要なハードウェア要件(CPU・GPUの役割)、推奨ツール、社内データを統合する「RAG」や「ファインチューニング」の技術的差異、そしてPoCから本番環境への移行プロセスを解説します。これを読めば、セキュリティ要件を満たしたAI開発の全体像と、自社に必要な環境構築の手順が明確になります。
目次
なぜ今「ローカルLLM」なのか?クラウド型との決定的な違い
まずは、一般的なクラウド型LLMと、自社環境で稼働させるローカルLLMの構造的な違いについて解説します。
1. セキュリティの確保:データが外部へ送信されない構造
クラウド型AIを利用する場合、データはAPI(ソフトウェアやプログラム同士をつなぎ、情報をやり取りするための「窓口」の仕組み)を経由して外部のサーバーで処理されます。
一方、ローカルLLMは、ネットワークから切断されたオフライン状態でも動作します。処理は目の前のPCや自社ネットワーク内のサーバーで完結するため、入力した機密情報や個人情報が外部へ送信されることはありません。この外部通信の遮断により、情報漏洩リスクを根本的に排除できる点が、医療や金融などの分野でローカルLLMが選ばれる理由です。
2. カスタマイズの実現:自社専用のAI環境構築
ローカルLLMを開発・導入することで、特定の業務に特化した独自のシステムを構築できます。社内の規定やマニュアルを参照する自動応答システムの運用や、外部ネットワークの障害に影響されない安定したシステムの稼働が可能になります。
製薬品質保証のGMP文書業務効率化SaaS「QAI Generator」なども、専門分野の要件に適合させたAI活用の実例です。
3. SLM(小規模言語モデル)という選択肢
ローカル環境で稼働させる際、パラメータ数を抑えたSLM(小規模言語モデル)を採用することも可能です。SLMは特定のタスクに特化しており、限られた計算リソースでも高速な推論処理を実行できるため、要件に応じたモデルの選択が重要になります。
失敗しない「ハードウェア選定」と推奨ツール

ローカルLLMの開発において、ハードウェアの構成は処理速度に直接影響します。
1. CPUとGPUの役割分担
LLMの推論処理においては、CPUとGPUの機能の違いを理解する必要があります。CPUはシステム全体の制御や順次処理を担当します。一方、GPUはLLMの推論に不可欠な大規模な行列計算を並列で実行します(帯域幅が広い)。実用的なトークン生成速度を得るためには、GPUによる処理が必須となります。
2. 推論処理に必須となる「VRAM」の要件
モデルを稼働させる上で最も重要な指標がGPUのVRAM(ビデオメモリ)容量です。例えば、パラメータ数が70億(7B)規模のモデルを稼働させる場合、最低でも8GBのVRAMが要求されます。より大規模なモデルや高速な処理能力が求められる要件では、24GB以上のVRAMを備えたハイエンドGPUや専用ワークステーションの導入が必要になります。

3. 開発・検証を効率化する主要ツール
ローカル環境の構築には、以下のツールが広く利用されています。
- Ollama: コマンドライン上でローカルLLMの構築と実行を行うオープンソースツール。Windows、macOS、Linuxに対応しています。
- LM Studio: GUI(グラフィカルユーザーインターフェース)を備え、モデルのダウンロードから実行までを視覚的に操作できるソフトウェアです。
- Dify: RAG機能やプロンプト生成機能を搭載し、AIアプリケーションの開発を効率化するオープンソースのプラットフォームです。
- vLLM: 高速かつメモリ効率に優れたLLM推論・サービングエンジン。独自の「PagedAttention」技術により、メモリの無駄を最小限に抑え、非常に高いスループット(処理能力)を実現しています。
「RAG」と「ファインチューニング」で自社データをAIに統合する
ローカルLLMに自社の固有データを反映させる技術には、主に2つのアプローチがあります。
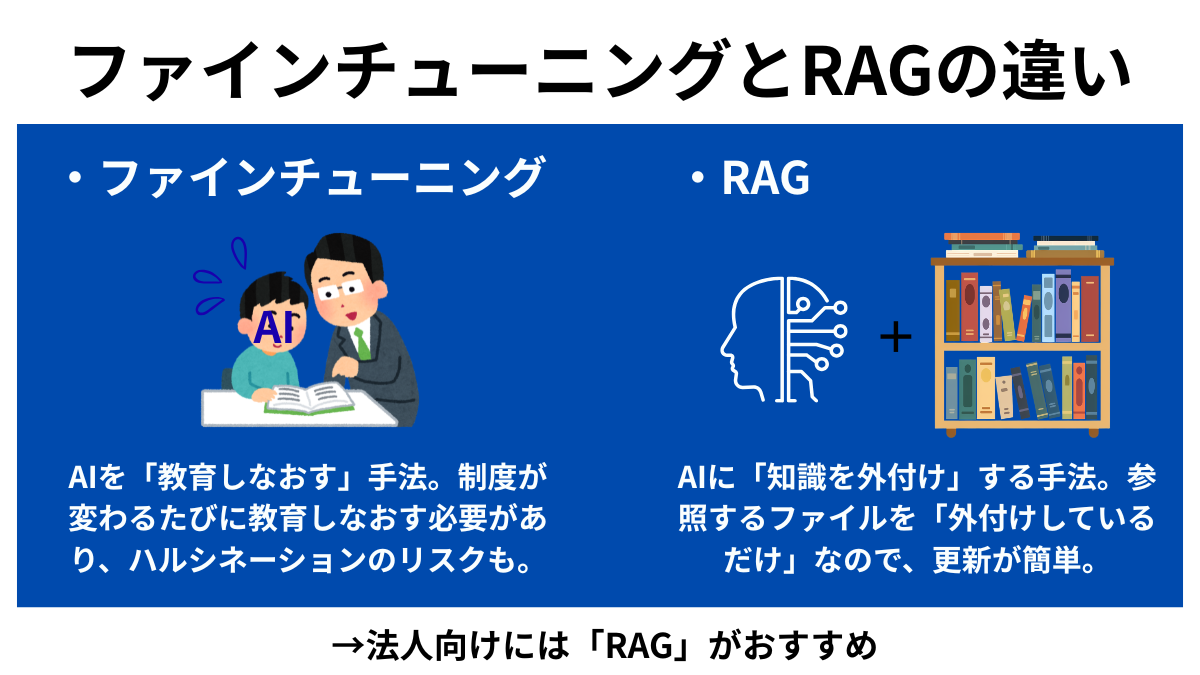
1. モデルのパラメータを更新するファインチューニング
ファインチューニングは、特定のデータセットを用いてLLM自体を再学習させ、内部のパラメータ(重み)を直接更新する手法です。特定のドメイン知識や独自の出力フォーマットをモデルに定着させる場合に採用されます。RAGと比較して、計算処理に要する高性能なGPUリソースと、品質の高い学習データを用意するコストが発生します。
2. 外部データベースを検索するRAG(検索拡張生成)
RAGは、ユーザーの入力に対して事前に構築したデータベースから関連情報を検索し、その結果をプロンプトに結合してLLMに回答を生成させる手法です。
ドキュメントを数値ベクトル化する埋め込み(embedding)モデルや、検索結果の関連性を再評価するリランキング技術を利用します。モデル自体のパラメータは変更しないため、最新情報の反映が容易であり、計算リソースの消費を抑えることができます。
更新が必要な社内規定や社内の情報を盛り込む際は、RAGの方が適していると言えるでしょう。
導入プロセスと自社に最適な環境構築

1. PoC(概念実証)による段階的な検証
ローカルLLMの開発は、スモールスタートによるPoCから開始します。少数の端末にOllamaやLM Studioを導入し、「要件を満たす回答精度が得られるか」「対象ハードウェアで実用的な推論速度が出力されるか」を検証します。
2. TCO(総所有コスト)の算出と運用体制
検証結果をもとに、本番環境への移行に向けたTCOを算出します。ローカルLLMはクラウドAPIの従量課金コストが発生しない反面、サーバーやGPUの初期導入費用、稼働時の電力コスト、保守管理の人的コストが必要となります。同時に、オンプレミス環境におけるデータ保護の基準やアクセス権限の管理体制を整備します。
3年間のTCO(総所有コスト)算出例
ローカルLLMを自社サーバーで構築し、社内専用のRAGシステムとして3年間運用した場合のTCO算出例です。700億(70B)パラメータ規模のオープンソースモデルを推論させる想定です。
| 費用区分 | 項目 | 費用目安(概算) | 内訳・備考 |
| 初期費用 (CAPEX) | ハードウェア調達費 | 3,000,000円 〜 5,000,000円 | AI推論用サーバー1台(高性能CPU、VRAM 48GB以上のGPU×2基程度)、ストレージ、ネットワーク機器など |
| 初期開発・環境構築費 | 2,500,000円 〜 | 弊社のPoCサービス「ココロミ」スタンダードプランの適用を想定。モデル選定、RAG構築、プロンプト調整など | |
| 運用費用 (OPEX) | 保守・システム管理費(年額) | 1,200,000円 〜 / 年 | 死活監視、モデル更新、セキュリティ対応。※自社対応の場合は人件費として換算 |
| 電力費・空調費(年額) | 150,000円 〜 / 年 | GPUの消費電力および冷却費。稼働率により変動 | |
| 3年間総額 | TCO(3年目安) | 約9,550,000円 〜 | 初期費用 +(運用費用 × 3年)の概算合計 |
クラウドAPIを利用したLLMサービスの場合、初期のハードウェア費用はかかりませんが、利用規模が拡大するにつれて従量課金のランニングコストが増加します。ハードウェアの償却期間を考慮し、中長期的な利用計画に基づいてクラウド型とローカル型のコスト分岐点を見極めることが重要です。
同時に、社内のセキュリティポリシーやコンプライアンス要件に適合しているかどうかも確認し、オンプレミス環境でのデータ保護やアクセス権限の管理体制を整備します。
まとめ:専門家による伴走型技術開発の活用

本記事では、セキュリティを確保したローカルLLM開発の技術要件について解説しました。
- オフライン稼働により、情報漏洩リスクを物理的に排除することが可能。
- 推論処理にはGPUの並列計算能力が不可欠であり、モデル規模に応じたVRAM容量の要件を満たす必要がある。
- 自社データの統合手法として、外部検索によるRAGと、パラメータ更新によるファインチューニングを要件に応じて選択する。
- PoCによる検証を経て、ハードウェア要件とTCOを明確化した上で本番環境へ移行する。
ローカルLLMの開発やRAG環境の構築には、高度な技術的知見が要求されます。自社に最適なAI開発の進行について支援が必要な場合は、株式会社EQUESのサービスをご活用ください。
- AI×DX寺子屋: AIに関する技術的な課題に対し、東大出身のAI専門家集団がチャットで解決策を提示するサービスです。
- ココロミ: 大規模開発を行う前の段階として、技術的な検証を行うPoCサービスを提供しております。

貴社のセキュリティ要件や業務課題に適合したAI導入プランをご提案いたします。詳細な要件定義や環境構築について、ぜひお気軽にお問い合わせください。


