
ビジネス現場でAI導入の需要が高まる中、「機密データを外部に出したくない」「自社独自の知識をAIに学習させたい」といった声も多く聞かれます。しかし、いざ始めようと思っても、人材不足や情報不足で足踏みしてしまう方も多いのではないでしょうか。
この記事では、ローカル環境でLLM(大規模言語モデル)をファインチューニングする具体的な手順や、必要なPCスペック、ツールについて丁寧に解説します。
【この記事を通してわかること】
- ローカルLLMとはなにか
- ファインチューニングとはなにか:RAGの違い
- ファインチューニングに必要なもの(スペックや環境など)
- ファインチューニングの手順
- トラブルシューティング
東大松尾研発のAIスタートアップである弊社、EQUESの知見をもとに、初心者の方でも全体の流れを把握できるよう構成しました。
目次
1. ローカルLLMとファインチューニングの基礎知識
まずは、なぜ今「ローカル環境」での「ファインチューニング」が注目されているのか、その背景を整理しましょう。
1.1 ローカルLLMを活用するメリット
ローカルLLMとは、クラウドサービスを利用せず、自身のPCや自社サーバー上で動作させるAIモデルを指します。最大のメリットはセキュリティです。外部のAPIにデータを送信しないため、社外秘の情報や顧客データを安全に扱うことができます。また、一度環境を構築すれば通信コストを抑えられ、オフラインでの利用も可能になります。
(ローカルLLMについて詳しく解説した記事もございますので詳しくはこちらをご覧ください!)
1.2 ファインチューニングとは何か
ファインチューニング(微調整)とは、学習済みのモデルに対して、特定のデータセットを追加で学習させる手法です。一般的なLLMは幅広い知識を持っていますが、以下のようなケースではファインチューニングが非常に有効です。
- 専門用語への対応: 医療や法務、特定の業界内だけで使われる特殊な用語を正しく理解・出力させたい場合。
- 出力形式の固定: 回答を必ず「JSON形式」や「特定のテンプレート」に従って出力させたい場合。
- 独自のトーン&マナー: 自社のブランドイメージに合わせた、特定の口調やキャラクター性を持たせたい場合
1.3 RAGとファインチューニングの違い
よく比較される手法に「RAG(検索拡張生成)」がありますが、ファインチューニングとRAGには明確な違いがあります。
| 特徴 | ファインチューニング | RAG (検索拡張生成) |
| 主な目的 | モデルの「振る舞い」や「形式」の習得 | 最新・外部情報の参照 |
| 知識の更新 | 再学習が必要(コスト高) | データベースの更新のみ(コスト低) |
| 得意なこと | 専門的な口調、特定の出力形式 | 社内規程や最新ニュースの回答 |
| データの量 | 質の高い数千件のペアが理想 | 既存のPDFやドキュメントをそのまま利用 |
目的に応じて、これらを使い分ける(あるいは組み合わせる)ことが重要です。
2. ファインチューニングに必要な環境とスペック
2.1 ファインチューニングの要はGPU性能
AIが学習(ファインチューニング)を行う際は、高性能なGPUが使用されます。その理由は2つあります。
1. 膨大な「並列計算」をこなすため
AIの学習は、数学的には非常に単純な「かけ算」と「たし算」を何兆回と繰り返す作業です。
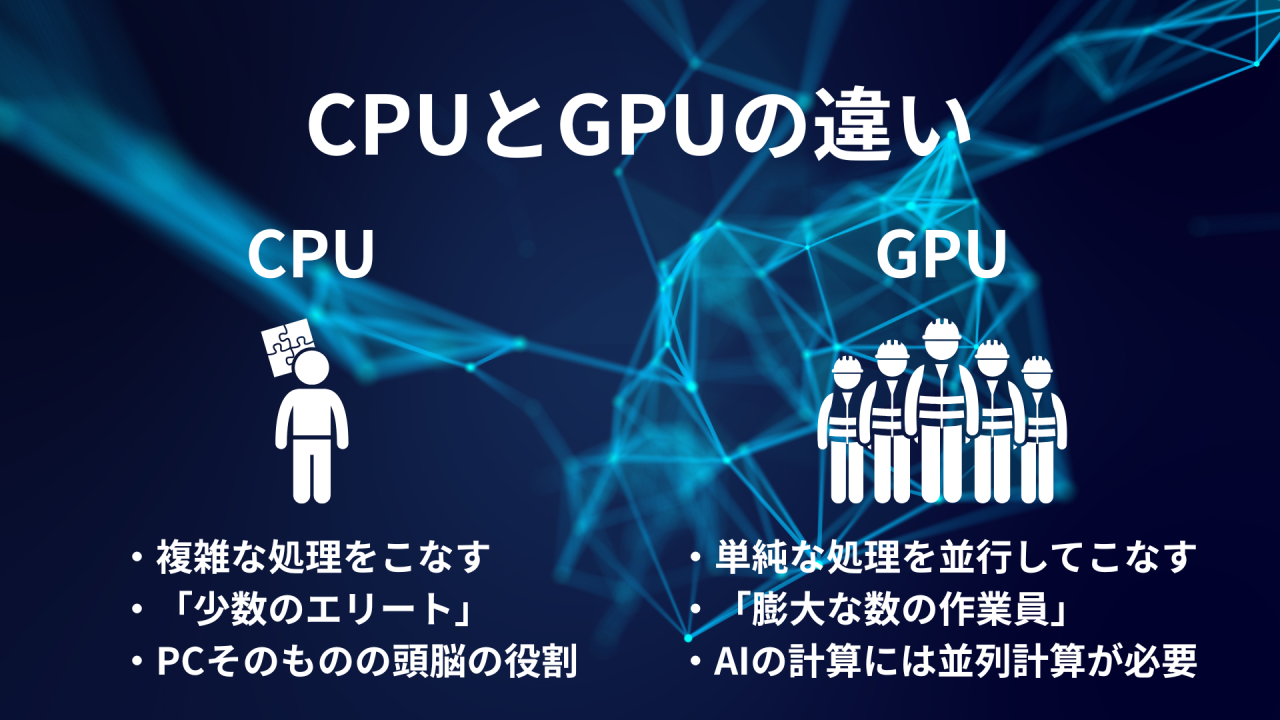
- CPU: 複雑な処理を順番にこなすのが得意な「少数のエリート集団」。
- GPU: 単純な計算を数千個同時にこなせる「膨大な数の作業員」。
LLMのような大規模なモデルでは、この「同時並行で計算する能力」がスピードに直結します。CPUだけで学習させようとすると、数年かかる作業がGPUなら数日で終わるほどの差が生まれます。
2. 「VRAM(ビデオメモリ)」がモデルの置き場所になるため
GPUスペックの中でも特に重要視されるのがVRAM(ビデオメモリ)の容量です。 DIYを行う際の作業机を想像してみてください。机が小さいと道具や材料を広げておけず、非常に不便な思いをすることでしょう。
AIの学習中は、AIモデル本体と学習データ、そして計算の途中で出た一時的な数値をすべて「広げて」置いておく必要があります。VRAMが足りないと、学習プログラムが動かずに停止してしまいます。
◼︎推奨されるGPUとVRAM
- GPU: NVIDIA製のGPUが推奨されます。CUDAという独自プラットフォームが広く普及しているためです。
- VRAM: 最低でも12GB以上(RTX 3060等)、本格的な開発なら24GB(RTX 3090/4090)や、A100/H100といった産業用GPUが理想的です。
- メモリ(RAM): 32GB以上を推奨します。
2.2 活用すべきツールとライブラリ
ローカルLLMのファインチューニングを支えるツールやライブラリは、「これらがないと事実上不可能」と言えるほど重要な役割を担っています。
それぞれのツールが具体的にどのような役割を果たしているのか、代表的なものを掘り下げて解説していきます。
◼︎基盤となるフレームワーク
まずは、AIの計算そのものを行うための土台です。
- PyTorch(パイトーチ)
- 役割: 深層学習(ディープラーニング)の計算を行う中心的なライブラリです。
- 特徴: Pythonとの親和性が非常に高く、研究者やエンジニアの間でデファクトスタンダードとなっています。多くの最新LLMはPyTorchで書かれており、デバッグやカスタマイズがしやすいため、ファインチューニングでも第一選択となります。
- TensorFlow(テンソルフロー)
- 役割: PyTorchと同様の役割を果たすGoogle製のフレームワークです。
- 特徴: 本番環境での大規模なデプロイや、Google Cloud/TPUを活用した環境に強みがあります。
◼︎Hugging Face(ハギングフェイス)のエコシステム
現代のLLM開発は、Hugging Faceが提供する一連のライブラリなしには語れません。
- Transformers
- 役割: Llama-3やMistralといったAIモデルや、テキストを数値に変換するトークナイザーを簡単にロードし、学習させるための共通APIを提供します。
- PEFT (Parameter-Efficient Fine-Tuning)
- 役割: パラメータ効率の良い微調整を実現する最重要ライブラリです。
- 特徴: モデル全体の重みを更新するのではなく、LoRA(Low-Rank Adaptation)やQLoRA(Quantized LoRA)どの技術を使って、追加したごく一部のパラメータだけを学習させます。これにより、VRAM消費を劇的に抑えることが可能です。
- VRAMが12GBならQLoRA(LoRAよりさらに軽量だが学習時間が長い)、24GB以上ならLoRAを視野にいれると良いでしょう。
- TRL (Transformer Reinforcement Learning)
- 役割: 教師あり学習(SFT)や、人間のフィードバックによる強化学習(RLHF)を効率的に行うためのライブラリです。
◼︎メモリと速度を最適化するツール
限られたローカルリソースを最大限に活用するための「補助エンジン」のようなツールです。
- bitsandbytes
- 役割: モデルを「量子化(4bit/8bit)」するためのライブラリです。
- 特徴: QLoRAを実現する際に必須となります。モデルの精度を極力落とさずに、消費するVRAMを数分の一に削減します。
- DeepSpeed / Accelerate
- 役割: 複数のGPUを使ったり、巨大なモデルを効率的に並列処理したりするための最適化ツールです。メモリの空きを賢くやりくりし、学習スピードを向上させます。
- Unsloth
- 役割: 最近注目を集めている、ファインチューニングを2〜5倍高速化し、メモリ使用量もさらに削減するライブラリです。
◼︎ツール活用の全体像
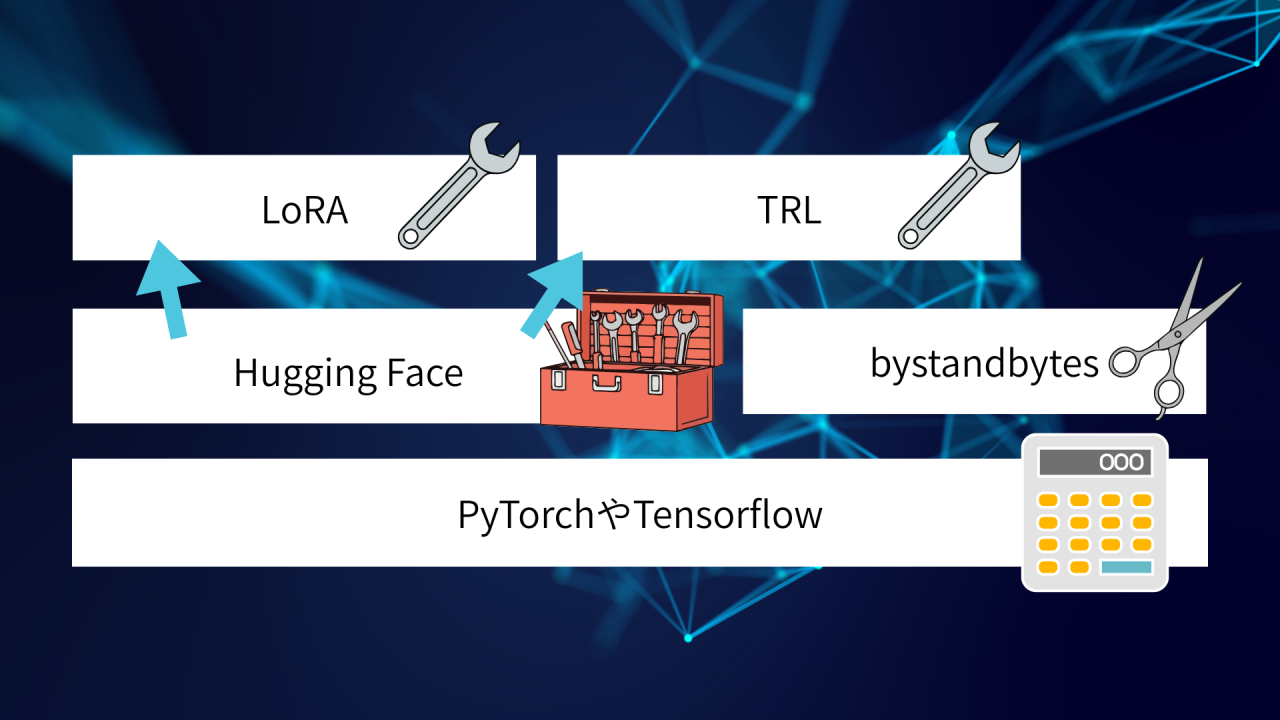
実際の開発現場では、これらを組み合わせて以下のように進めます。
- PyTorchという計算土台の上で、
- Hugging Face Transformersを使ってモデルを呼び出し、
- bitsandbytesでモデルを軽くして(量子化)、
- PEFT (LoRA)で特定の知識を効率よく学習させ、
- TRLで学習の進行(Trainer)を管理する。
2.3 学習データの準備
ファインチューニングの成否はデータの質に依存します。
- 形式: JSONL形式などで「指示(Instruction)」と「回答(Output)」のペアを用意するのが一般的です。
- 量: タスクによりますが、数百〜数千件の高品質なデータがあれば、特定の傾向を学習させることが可能です。
3. ローカルLLMでファインチューニングする手順
それでは、具体的なローカルLLM ファインチューニングのやり方をステップごとに見ていきましょう。
3.1 まずはベースモデルの選定
まずはベースとなるモデルを選びます。日本語性能が高い「Llama-3」ベースのモデルや、Mistralなどが人気です。Hugging Faceなどでライセンスを確認し、商用利用が可能かチェックしましょう。
3.2 環境構築
Python環境を構築し、必要なライブラリをインストールします。
(参照元: PyTorch Official Installation Guide)
3.3 QLoRAによる学習の実行
VRAMを節約するために「QLoRA」の量子化手法を用いるのが一般的です(先述)。これにより、家庭用PCレベルのGPUでも、大規模なモデルを効率よく学習させることができます。
3.4 評価とテスト
学習が終わったら、意図した通りの回答ができるかテストします。過学習(特定のデータにだけ詳しくなり、応用が利かなくなる状態)が起きていないか確認することが大切です。
4. よくある失敗とトラブルシューティング

スムーズに進めるために、あらかじめ落とし穴を知っておきましょう。
◼︎メモリ不足(Out of Memory)への対処
学習中に「CUDA out of memory」というエラーが出ることがあります。これはGPUのメモリが足りないサインです。
- 対処法: バッチサイズを小さくする、モデルを量子化(4bit等)して読み込む、あるいはより軽量なモデルに変更することを検討してください。
◼︎ 回答精度の低下(カタストロフィック忘却)
特定の知識を詰め込みすぎると、AIが元々持っていた一般的な会話能力が失われることがあります。
- 対処法: 元の学習データに近い汎用的なデータセットを混ぜて学習させる(リプレイ法)などが有効です。
5. まとめ
今回の記事では、ローカルLLMでのファインチューニングのやり方について解説しました。
- ローカル環境なら、セキュリティを確保しながら自社専用AIを作れる
- GPUスペック(特にVRAM)が成功の鍵を握る
- QLoRAなどの技術を使えば、限られたリソースでも効率的に学習が可能
自社での導入やPoCについて、「もっと具体的に相談したい」「技術的なサポートが欲しい」とお考えの際は、ぜひ株式会社EQUESへお問い合わせください。弊社は東京大学松尾研究所発のスタートアップとして、製薬分野をはじめとする高度なAI技術開発を支援しています。

特に「AI×DX寺子屋」では、月額20万円から東大出身の専門家にチャットで相談し放題のプランもご用意しております。まずは小さな一歩から、貴社のAI活用をサポートさせていただきます。


