
このたび弊社は、製薬業界向けの大規模言語モデル(LLM)「JPharmatron-7B」を開発・発表いたしました。
「JPharmatron-7B」は、薬学・製薬分野の大規模データセットをもとに学習されたモデルで、製薬文書作成など実務での活用を想定して設計されています。70億パラメータの比較的軽量な構造で、社内ネットワークやローカル環境でも運用可能です。
また、製薬・薬学分野における評価基準の整備を目的として、日本薬剤師国家試験、名寄せ、齟齬点検といった3つのタスクからなる独自ベンチマーク「JPharmaBench」もあわせて開発・公開いたしました。
本モデルは、既存の国内外のベンチマークにおいて、同規模のオープンモデルである「Meditron3-Qwen2.5-7B」や「Llama-3.1-Swallow8B-Instruct-v0.3」をすべての評価項目で上回る性能を記録しており、同パラメータ規模における最高水準の性能を達成しています。なお、本開発は経済産業省/NEDOによる「GENIAC」プロジェクトの一環として実施されています。
今後は、EQUESが提供する製薬業界向けAIソリューション「QAI」への実装や、各種共同研究への活用を見据えております。
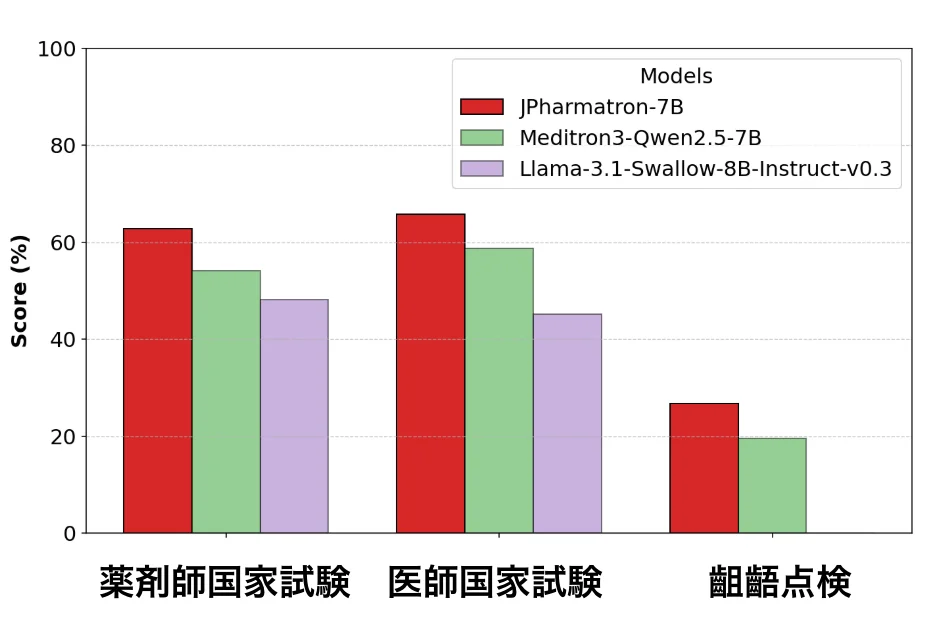
JPharmatronおよびJPharmaBenchは、HuggingFace上でも公開しておりますので、ぜひご覧ください。
▼JPharmatron
https://huggingface.co/EQUES/JPharmatron-7B
▼JPharmaBench
https://huggingface.co/collections/EQUES/jpharmabench-680a34acfe96870e41d050d8
本モデルにご関心のある方は、以下よりお気軽にお問い合わせください。


